When evaluating video inpainting methods, people often use different video sources. Commonly-used datasets are video segmentation datasets like DAVIS 2017 and YouTube-VOS because they provide foreground masks. However, they are not specifically designed for video inpainting: they don’t give labels to indicate whether the video is hard for video inpainting, and if so, why.
For this reason, we propose attributes that are likely to affect the video inpainting model performance — camera motion, foreground motion, background scene motion, and foreground displacement — and label them on DAVIS 2017. This can help us evaluate those videos’ difficulties for the video inpainting task. However, labeling a video objectively is a challenge for humans since everyone has their own criterion; therefore, we propose a set of automatic classifiers. We hope the new-annotated dataset will be a guide for researchers to improve their algorithms.
Classifier Performance
In the new dataset, we divide the videos’ motion into binary labels. It will be either high motion video or low motion video and evaluate the performance on the DAVIS dataset.
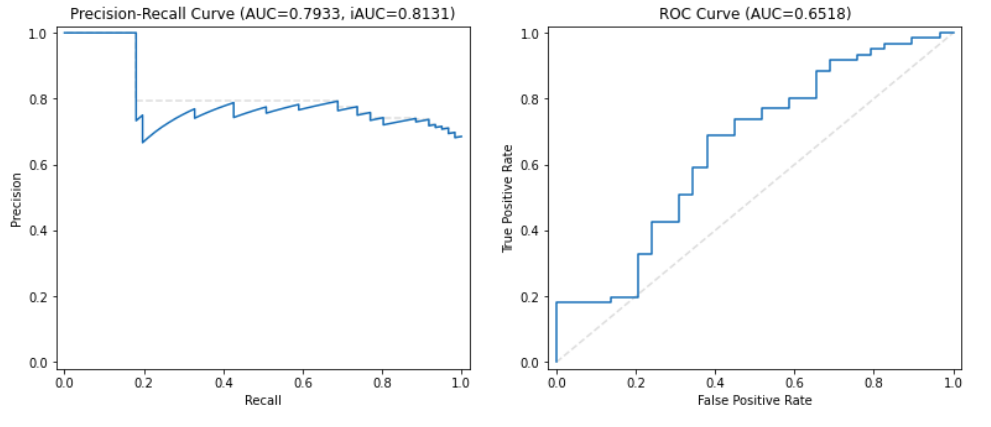
Camera motion
In low camera motion video, most of the background textures are observed in both frames and that they are completely different on the right.
Camera Motion Performance
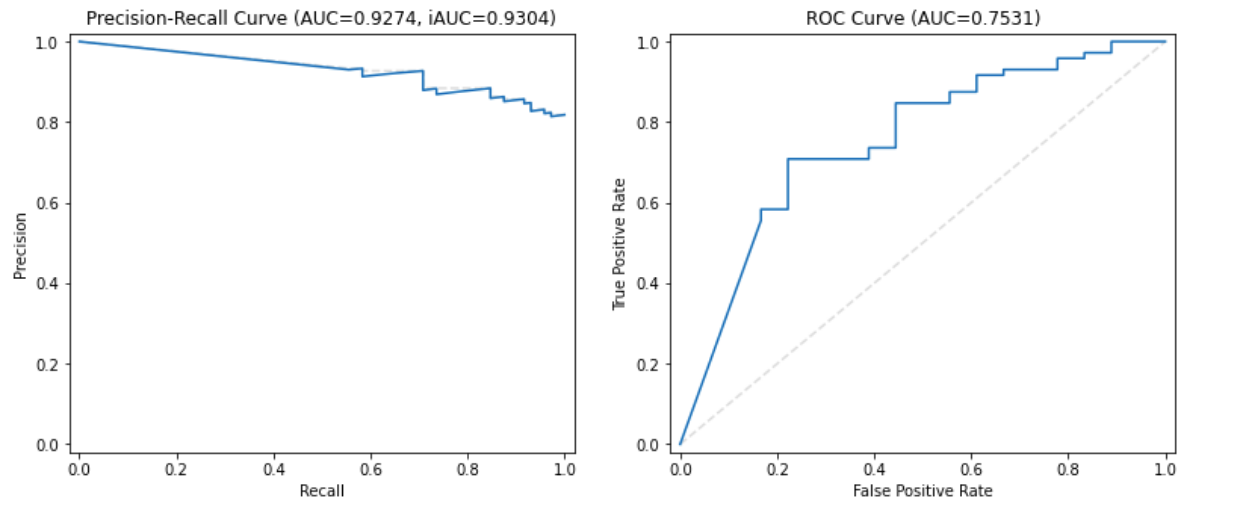
Foreground motion
In a low foreground motion video, the foreground object’s appearance is consistent across the frames. However, in high foreground motion video, the object tends to change its posture very much.
Foreground Motion Performance
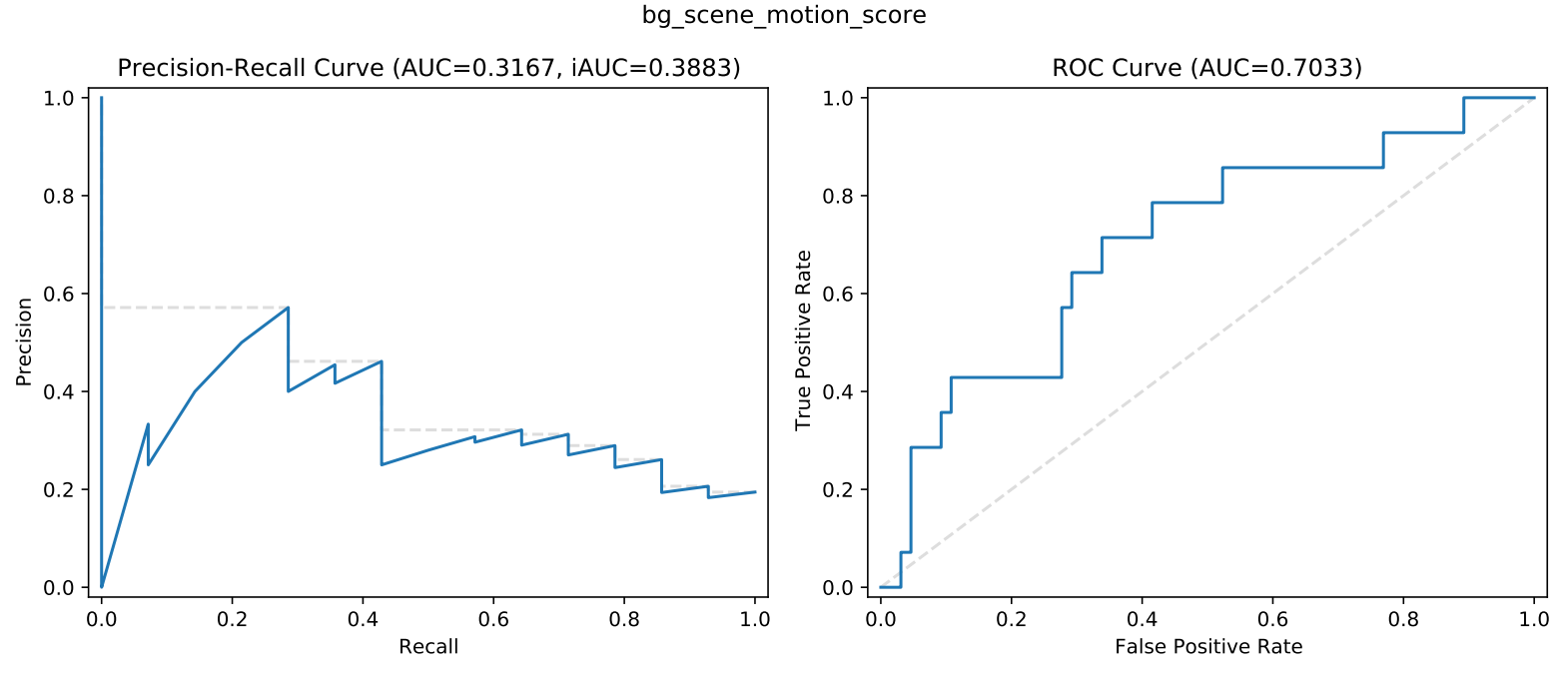
Background scene motion
The high scenic motion video will obtain moving components like water in the background, and the low scenic motion video will obtain static backgrounds like rock and trees.
Background Scene Motion Performance
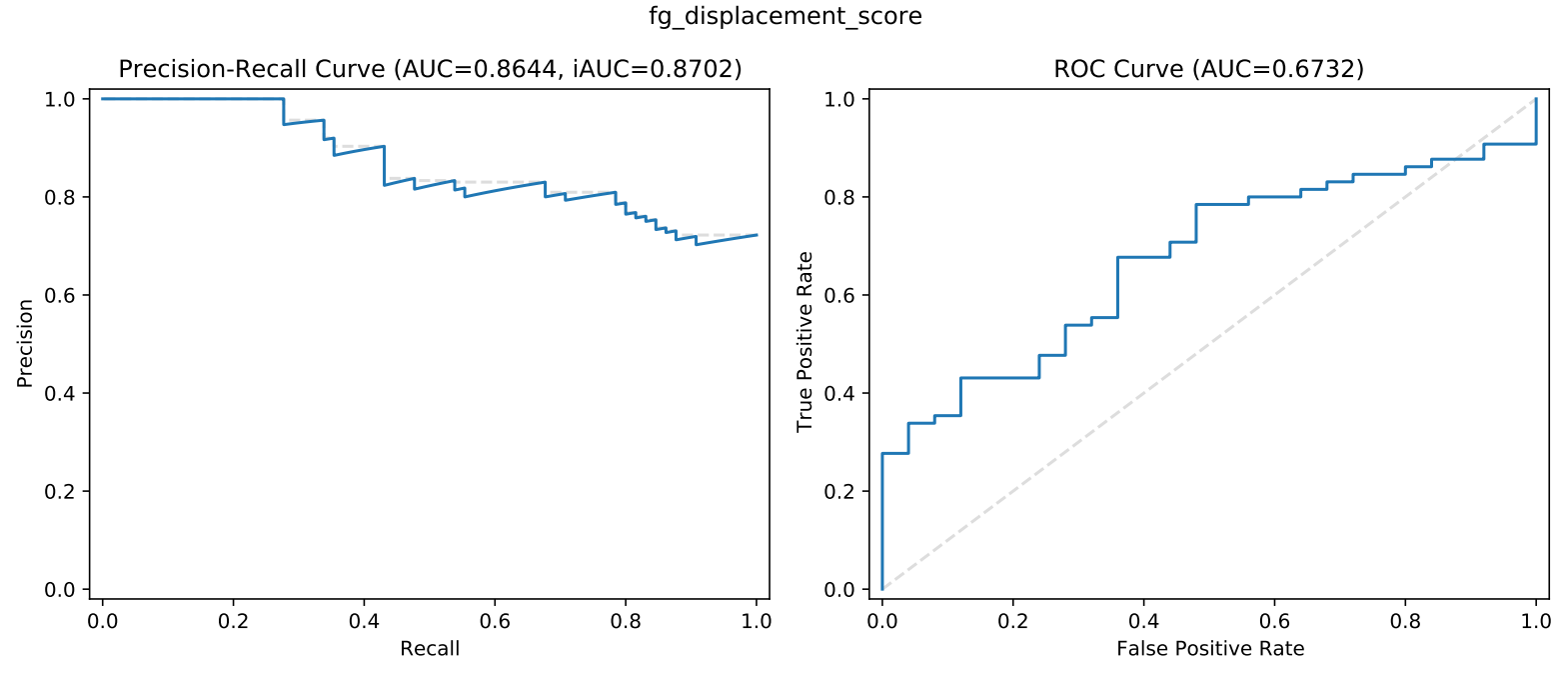
Foreground displacement
The high foreground displacement videos can often reveal different parts of the occluded background over time.
 Photo by rawpixel on Unsplash
Photo by rawpixel on Unsplash